提取人声和纯音乐
音频信号处理中提取人声和纯音乐是一个常见的问题,涉及到信号处理、音频特征提取、机器学习等多个领域。以下是针对这个问题的一些建议和方法:
1. 音频信号的表示
音频信号可以通过时域波形图和频谱图进行表示。时域波形图显示了音频信号随时间的变化,而频谱图则展示了不同频率成分的能量。这两种表示形式均对音频信号的特征提取和音乐人声分离有重要意义。
2. 短时傅里叶变换(ShortTime Fourier Transform,STFT)
STFT是一种常用的时频分析方法,可以将音频信号分解成不同频率成分随时间的变化。对音频进行STFT可以得到时频图,从中可以观察到音乐和人声的频率特征。
3. 基于深度学习的方法
近年来,基于深度学习的方法在音频信号处理领域取得了许多进展。使用深度学习模型,如卷积神经网络(Convolutional Neural Network,CNN)或循环神经网络(Recurrent Neural Network,RNN),可以学习音频信号的特征并进行音乐人声的分离。
4. 基于频谱特征的分离方法
基于频谱特征的分离方法包括盲源分离(Blind Source Separation,BSS)和独立成分分析(Independent Component Analysis,ICA)等。这些方法利用音频信号的统计特性来对音乐和人声进行分离。
5. 开源工具和库
有许多开源的工具和库可以用于音频信号处理,如Librosa、Pydub和FFmpeg等。这些工具提供了丰富的音频处理函数和算法,可以用于提取人声和纯音乐。
总结
如果你是在从事音频信号处理方面的工作,可以尝试结合以上方法,根据具体的应用场景选择合适的方法。也可以通过阅读相关领域的论文和文献,参与线上线下的相关讨论和培训,不断提升自己在音频处理领域的专业知识和技能。
希望这些信息能对你有所帮助,如有更多问题,欢迎继续交流!









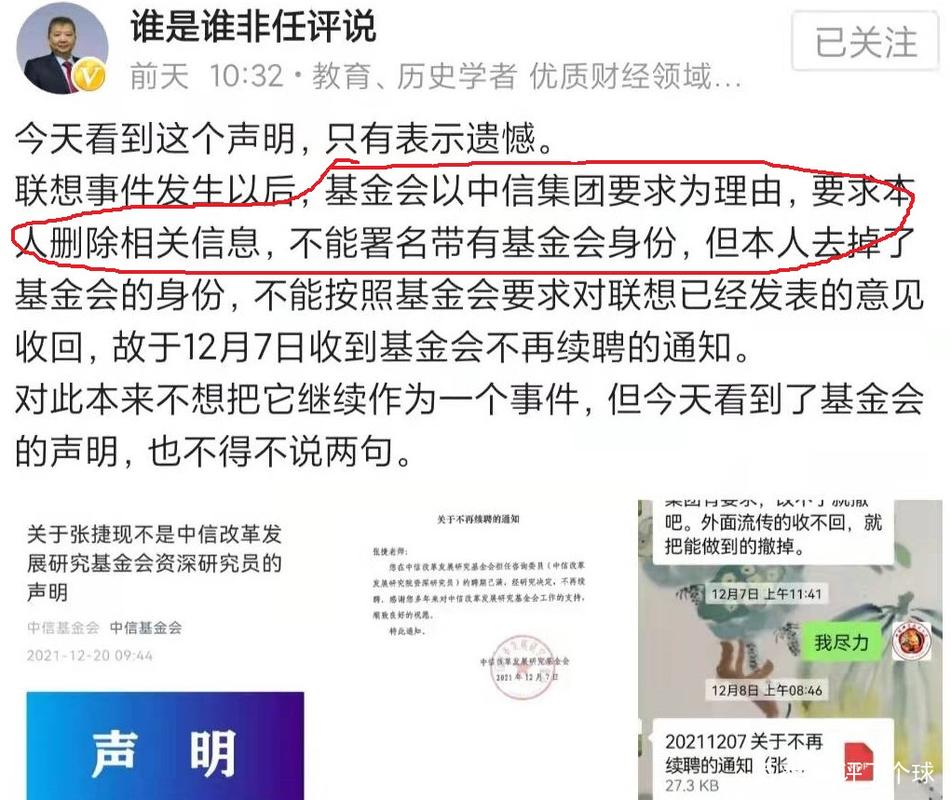
皙勤
这家伙太懒。。。
- 暂无未发布任何投稿。